

转载来源
演示
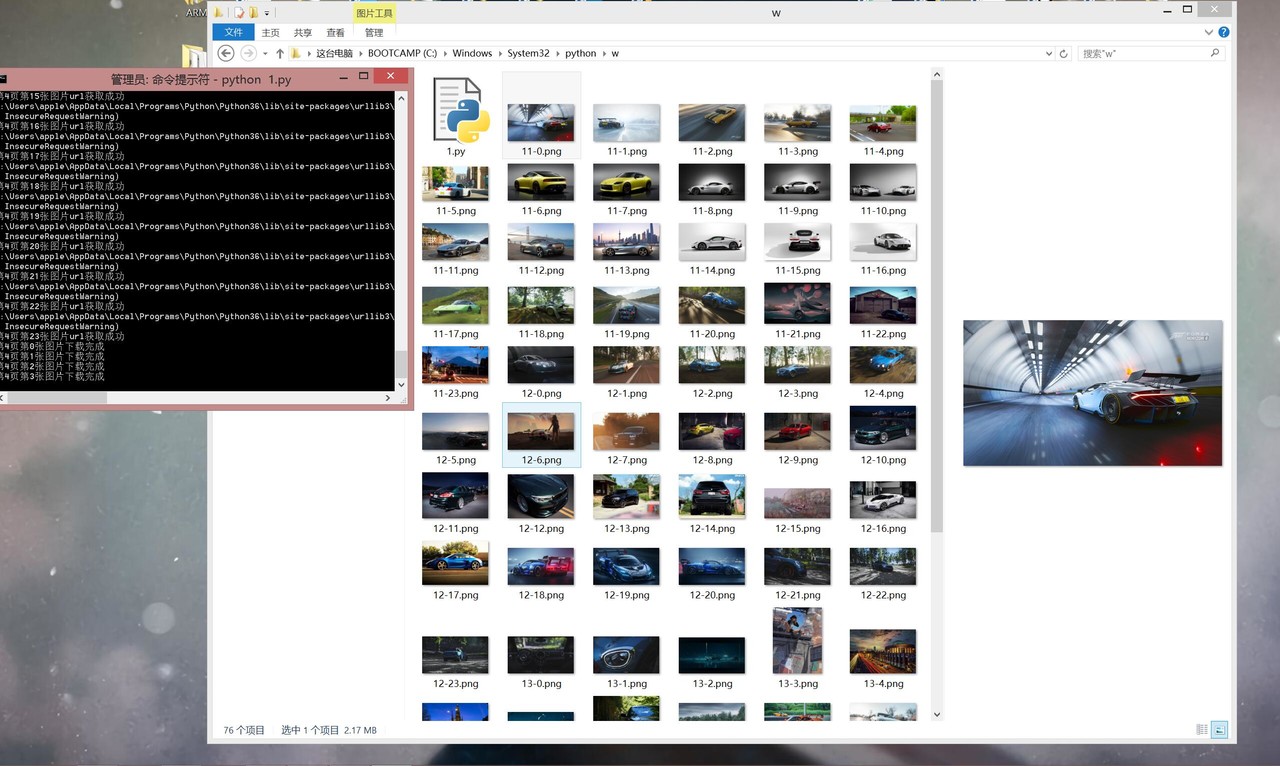
食用方法
import requests
import re
import time
from bs4 import BeautifulSoup
'''
总思路:
0.在”https://wallhaven.cc/toplist“加“?page=页数”可进行翻页
1.使用Chrome开发工具,发现在主页有两种图片的url,一个为缩略图可直接下载,一个为原图,需要进入下载。此次选择下载原图。
2.观察网页源代码,原图url在<a class="perview">中,使用BeautifulSoup和正则表达式获取ID。
3.获取ID后进入单图片页面,发现有3个带有![]() 标签的片段,其中第三个片段的src为图片下载url。
4.获取下载url后便可下载到制定文件夹中。
'''
'''
函数说明:
getPic_ID():获取每张图的ID
getPic_HTML():获取每张图的url
Download():根据url下载并保存图片
'''
def getPic_ID(pic_id, page, header):
url = "https://wallhaven.cc/search?q=car&categories=110&purity=100&sorting=date_added&order=desc&page="+str(page)
r = requests.get(url = url,headers = header,verify = False)
soup = BeautifulSoup(r.text, 'html.parser')
for tag in soup.find_all("a",class_="preview"):
picURL = re.findall('href="https://wallhaven.cc/w/(.*?)"',str(tag))
pic_id.append(picURL[0]) #findall元素问列表,我们的目的是存储str类型的id
print(pic_id)
return pic_id
def getPic_HTML(picHTML, pic_id, page, header):
for i in range(len(pic_id)):
pic_url2='https://wallhaven.cc/w/'+pic_id[i]
try:
r = requests.get(url = pic_url2, headers = header,verify = False)
#print(r.text)
soup = BeautifulSoup(r.text, 'html.parser')
items = soup.find_all('img')
picHTML.append(items[2].attrs['src']) #第3个
标签的片段,其中第三个片段的src为图片下载url。
4.获取下载url后便可下载到制定文件夹中。
'''
'''
函数说明:
getPic_ID():获取每张图的ID
getPic_HTML():获取每张图的url
Download():根据url下载并保存图片
'''
def getPic_ID(pic_id, page, header):
url = "https://wallhaven.cc/search?q=car&categories=110&purity=100&sorting=date_added&order=desc&page="+str(page)
r = requests.get(url = url,headers = header,verify = False)
soup = BeautifulSoup(r.text, 'html.parser')
for tag in soup.find_all("a",class_="preview"):
picURL = re.findall('href="https://wallhaven.cc/w/(.*?)"',str(tag))
pic_id.append(picURL[0]) #findall元素问列表,我们的目的是存储str类型的id
print(pic_id)
return pic_id
def getPic_HTML(picHTML, pic_id, page, header):
for i in range(len(pic_id)):
pic_url2='https://wallhaven.cc/w/'+pic_id[i]
try:
r = requests.get(url = pic_url2, headers = header,verify = False)
#print(r.text)
soup = BeautifulSoup(r.text, 'html.parser')
items = soup.find_all('img')
picHTML.append(items[2].attrs['src']) #第3个![]() 是可下载的url
print("第"+str(page)+"页第"+str(i)+"张图片url获取成功")
except:
print("第"+str(page)+"页第"+str(i)+"张图片url获取失败")
# for i in range(len(picHTML)):
# print(picHTML[i])
return picHTML
def Download(picHTML, page):
path = 'C:/Windows/System32/python/w/1' #路径自行设定
for i in range(len(picHTML)):
html = picHTML[i]
img_name = path + str(page)+"-"+str(i)+'.png' #图片名称
try:
data = requests.get(picHTML[i])
with open(img_name, 'wb') as file:
file.write(data.content)
file.flush()
print("第"+str(page)+"页第"+str(i)+"张图片下载完成")
except:
print("第"+str(page)+"页第"+str(i)+"张图片下载失败")
print("第"+str(page)+"页爬取完成")
def main():
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1'
}
for page in range(1,6):#此为1~5页,自行设定
pic_id = [] #每张图片的id列表
picHTML = [] #每张图片的下载url列表
getPic_ID(pic_id, page, header)
getPic_HTML(picHTML, pic_id, page, header)
Download(picHTML, page)
main()
是可下载的url
print("第"+str(page)+"页第"+str(i)+"张图片url获取成功")
except:
print("第"+str(page)+"页第"+str(i)+"张图片url获取失败")
# for i in range(len(picHTML)):
# print(picHTML[i])
return picHTML
def Download(picHTML, page):
path = 'C:/Windows/System32/python/w/1' #路径自行设定
for i in range(len(picHTML)):
html = picHTML[i]
img_name = path + str(page)+"-"+str(i)+'.png' #图片名称
try:
data = requests.get(picHTML[i])
with open(img_name, 'wb') as file:
file.write(data.content)
file.flush()
print("第"+str(page)+"页第"+str(i)+"张图片下载完成")
except:
print("第"+str(page)+"页第"+str(i)+"张图片下载失败")
print("第"+str(page)+"页爬取完成")
def main():
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1'
}
for page in range(1,6):#此为1~5页,自行设定
pic_id = [] #每张图片的id列表
picHTML = [] #每张图片的下载url列表
getPic_ID(pic_id, page, header)
getPic_HTML(picHTML, pic_id, page, header)
Download(picHTML, page)
main()
更换下载内容
修改此处代码
def getPic_ID(pic_id, page, header):
url = "https://wallhaven.cc/search?q=car&categories=110&purity=100&sorting=date_added&order=desc&page="+str(page)
r = requests.get(url = url,headers = header,verify = False)
将此处url换成你想要的链接
-
进入wallhaven官网https://wallhaven.cc/
-
搜索你要的内容,例如girls
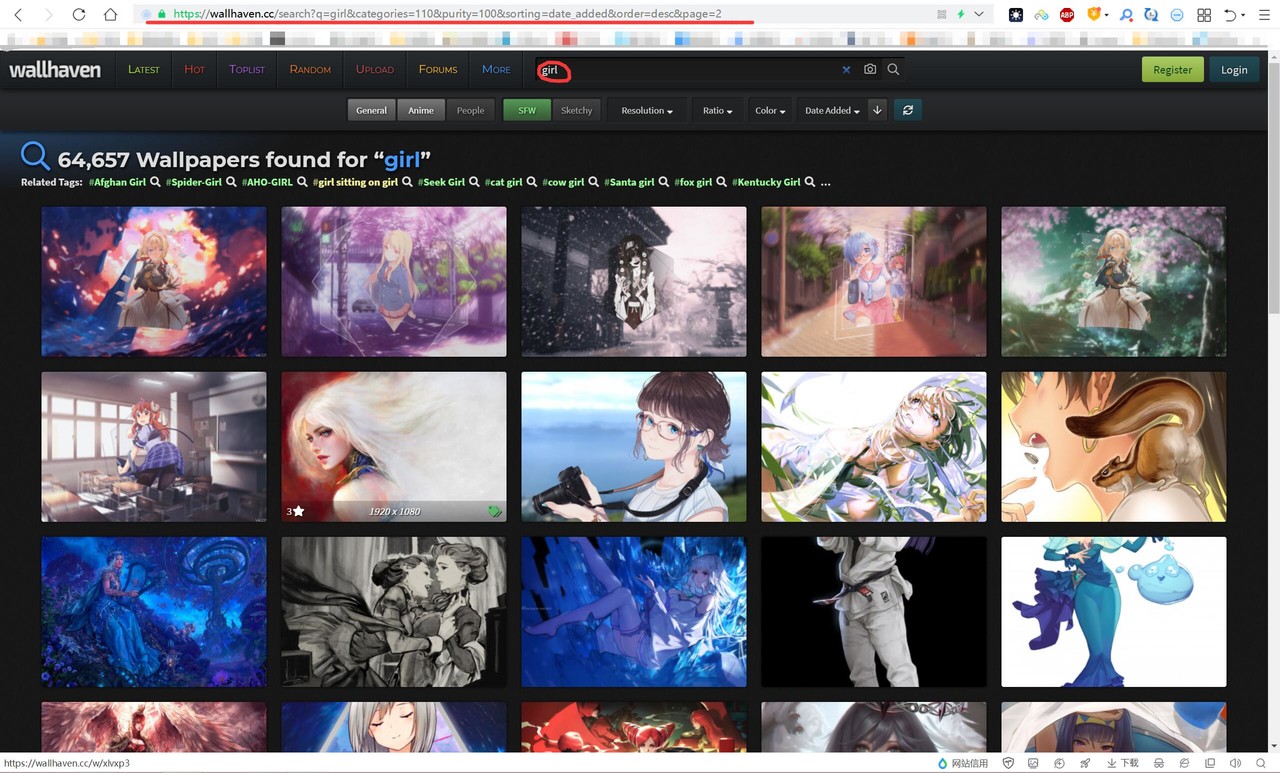
-
得到url
https://wallhaven.cc/search?q=girl&categories=110&purity=100&sorting=date_added&order=desc&page=2删除最后的页码即可
https://wallhaven.cc/search?q=girl&categories=110&purity=100&sorting=date_added&order=desc&page=
更换下载图片的位置
修改此处的代码
def Download(picHTML, page):
path = 'C:/Windows/System32/python/w/1' #路径自行设定
壁纸分享

 个人主页
个人主页 自用API
自用API 音乐盒
音乐盒 赵二狗
赵二狗
Comments | 0 条评论